elasticsearch
docker 安装 elasticsearch
1 | docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.8.0 |
kibana
1 | docker run -d --name kibana --link elasticsearch:elasticsearch -p 5601:5601 kibana:7.8.0 |
docker 安装 elasticsearch-head
1 | docker run -d --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5 |
Elasticsearch-head 数据浏览无显示解决办法
https://blog.csdn.net/weixin_42830314/article/details/108316045
进入 es-head 容器里面的 _site目录修改配置文件vendor.js
6886行
contentType: "application/x-www-form-urlencoded
改成contentType: "application/json;charset=UTF-8"7573行
var inspectData = s.contentType === "application/x-www-form-urlencoded" &&
改成var inspectData = s.contentType === “application/json;charset=UTF-8” &&
Elasticsearch-head 跨域配置
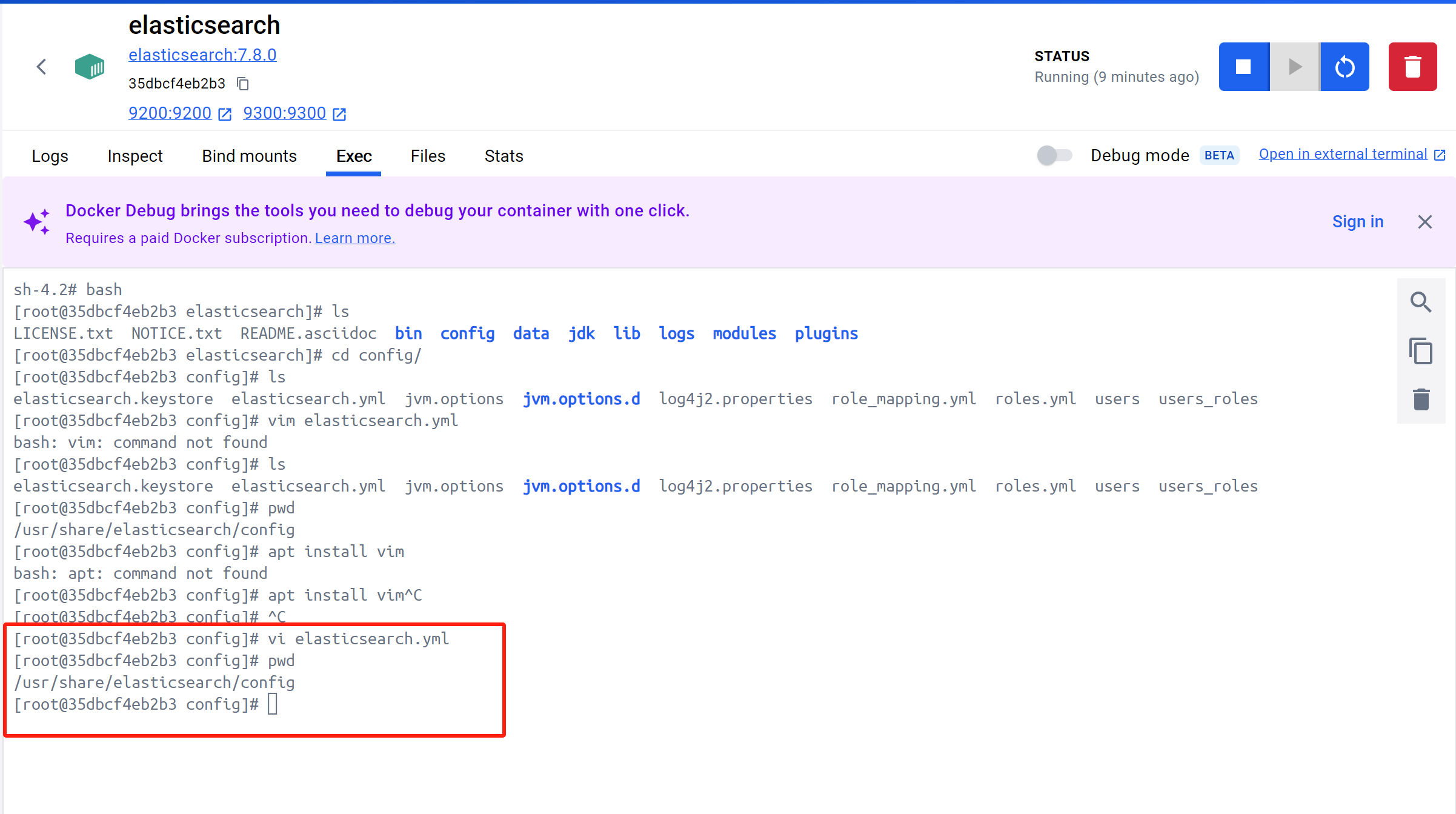
vi config/elasticsearch.yml加入2个参数,并重启
1 | http.cors.enabled: true |
ELK
from 狂神说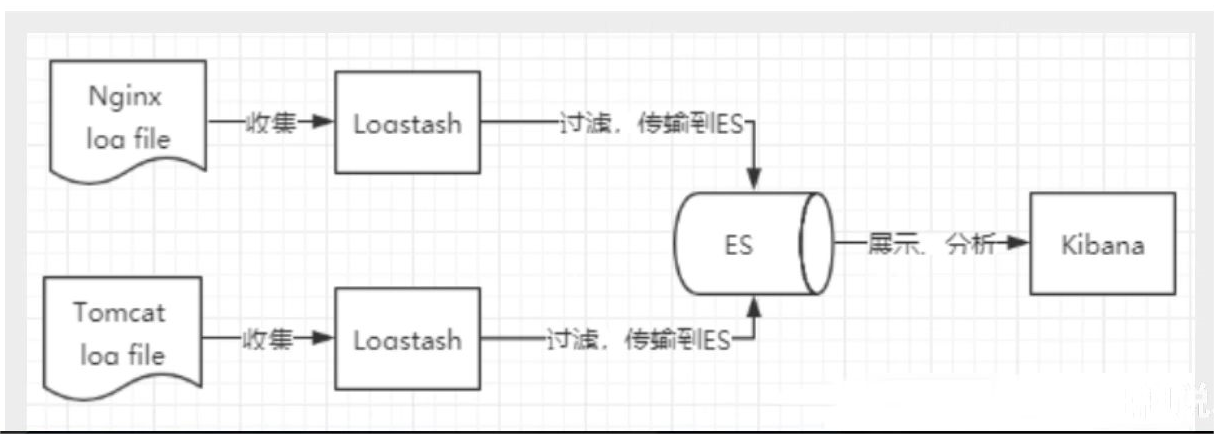
核心概念
- 索引
- 字段类型
- 文档
| db | es |
|---|---|
| 数据库 | 索引 |
| 表 | types |
| 行 | 文档 |
| 字段 | fields |
es 安装 ik 分词器
- 安装
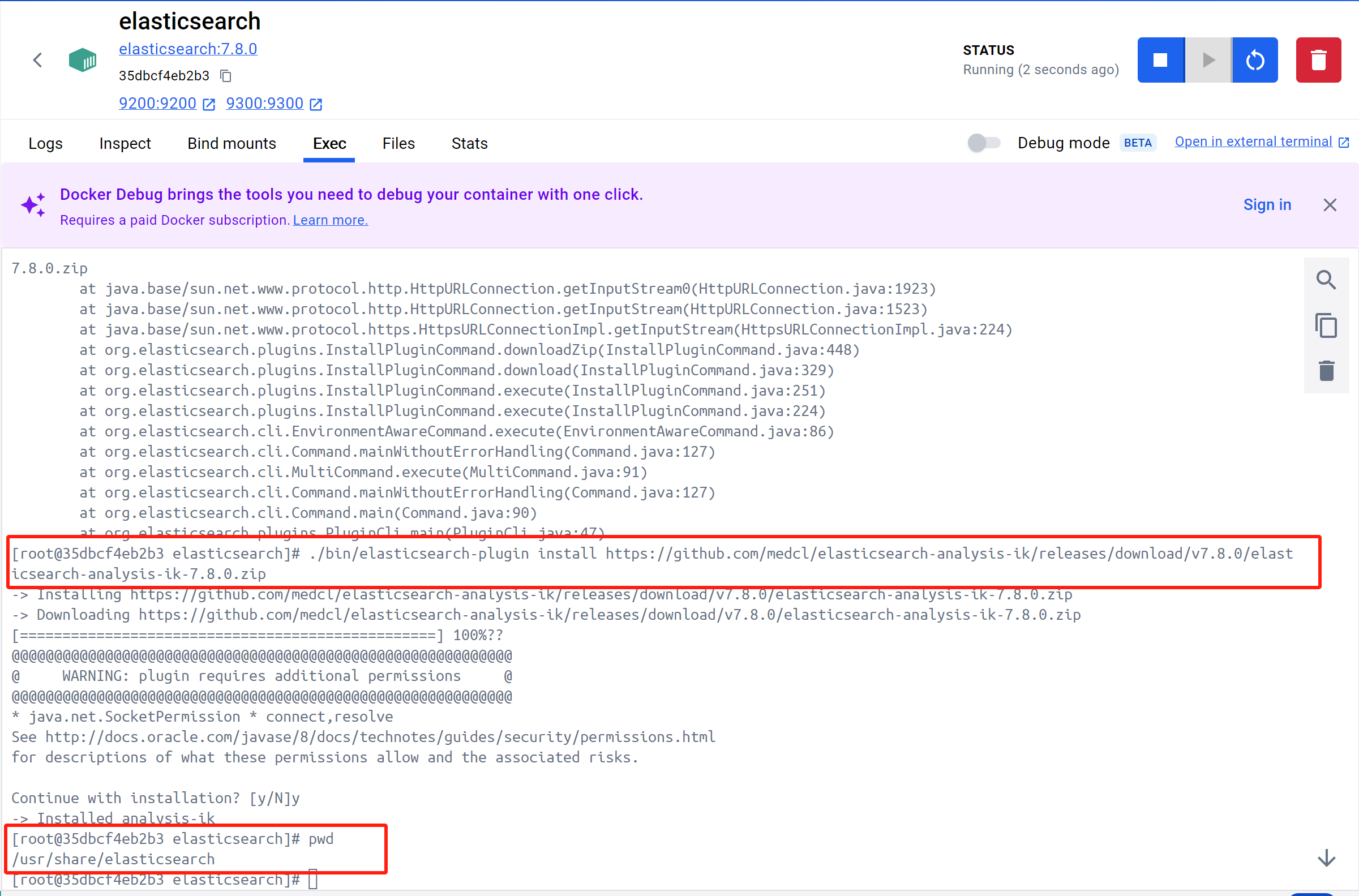
1 | ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.7.0/elasticsearch-analysis-ik-7.7.0.zip |
- 基本使用
restful api
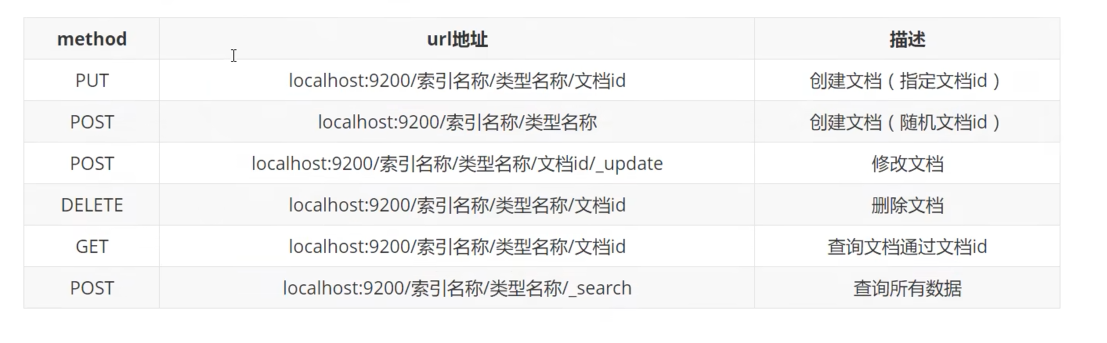
PUT /索引名/类型/文档id
1 | GET _analyze |
1 | # 分词器使用 |
精确查询
tram查询直接通过倒排索引进行指定词条的查询,效率非常高
- term, 世界查询精确的
- match, 使用分词器查询(先分析文档,然后通过分析的文档进行查询!)
两个类型 text 和 keyword
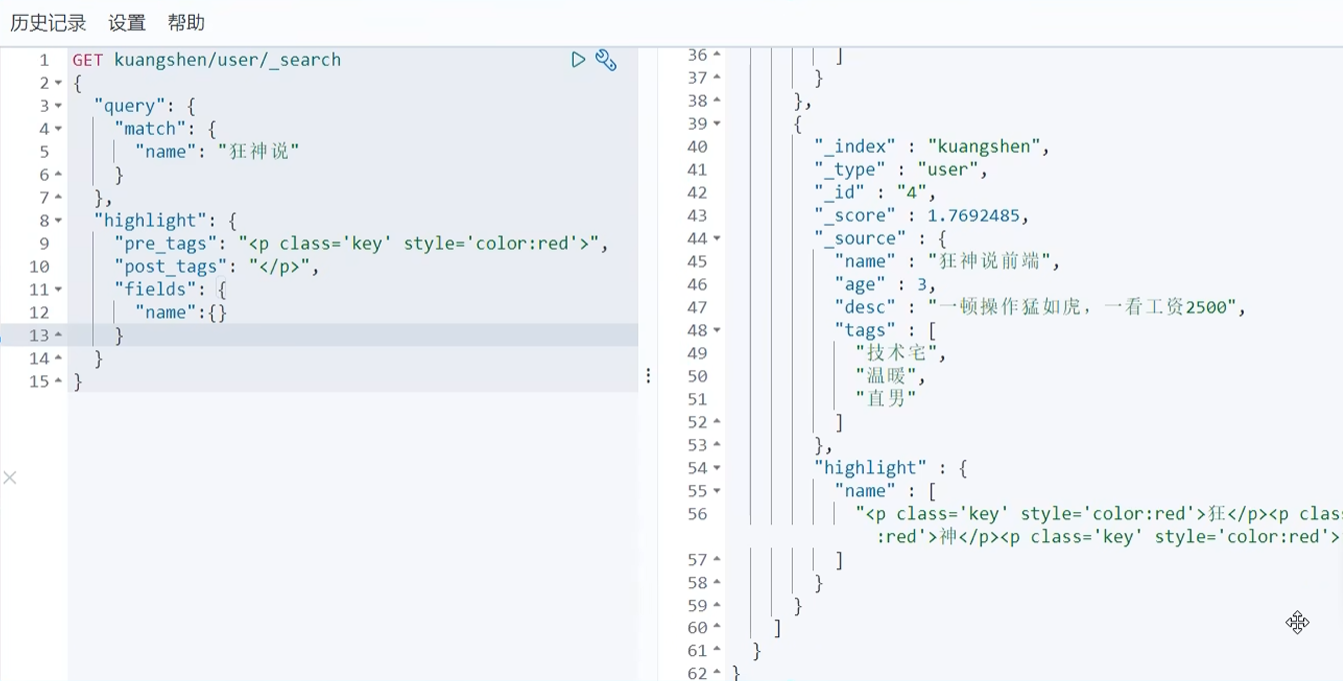
高亮查询
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.